Where we consider the problem of putting an i.i.d. prior on the entries of \(\beta\) and using a mean field approximation for variational inference.
Specifically, we put a spike and slab prior on \(\beta_j = b_j\gamma_j\) for \(j \in [p]\). Where \(b_j \sim N(0, \sigma^2)\) gives the distribution of non-zero effects, and and \(\gamma_j \sim Bernoulli(\pi)\). That is, the effect is non-zero with probability \(\pi\).
The problem we demonstrate, is that due to the mode matching behavior of the “reverse” KL divergence, which is minimized in variational inference, the posterior on \(q(\gamma_1, \dots, \gamma_p)\) will tend to concentrate instead of accurately representing uncertainty. Furthermore, due to strong dependence among the posterior means.
We work with a simplified version of RSS assuming we observe \(z\)-scores \(\hat z\).
sim_zscores <-function(n, p){ X <- logisticsusie:::sim_X(n=n, p = p, length_scale =5) R <-cor(X) z <-rep(0, p) z[10] <-5 zhat <- (R %*% z)[,1] + mvtnorm::rmvnorm(1, sigma=R)[1,]return(list(zhat = zhat, z=z, R=R))}init_q <-function(p){ q =list(mu =rep(0, p),var =rep(1, p),alpha =rep(1/p, p) )return(q)}run_sim <-function(n =100, p =50, tau0=1, prior_logit =-3){ sim <-sim_zscores(n = n, p = p) q <-init_q(p) prior_logit <-rep(prior_logit, p)for(i in1:100){ q <-with(sim, rssvb(zhat, q, R, tau0, prior_logit)) } sim$q <- qreturn(sim)}
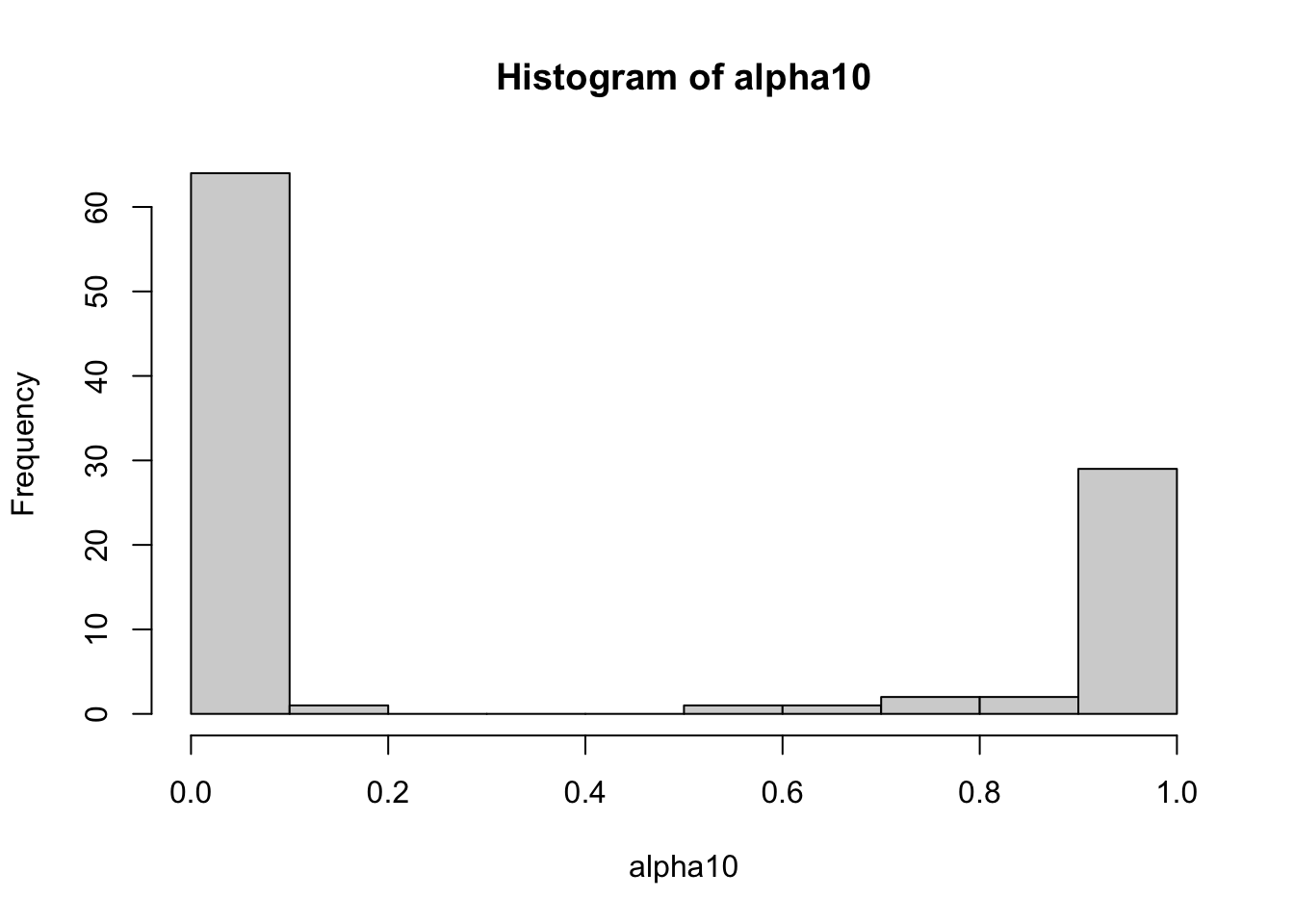
For 100 independent simulations, we simulate \(50\) dependent \(z\)-scores. The true non-zero \(z\)-score is at index \(10\) with \(\mathbb E[\hat z_{10}] = 5\). However, over half the time, the VB approximation confidently selects another nearby feature.
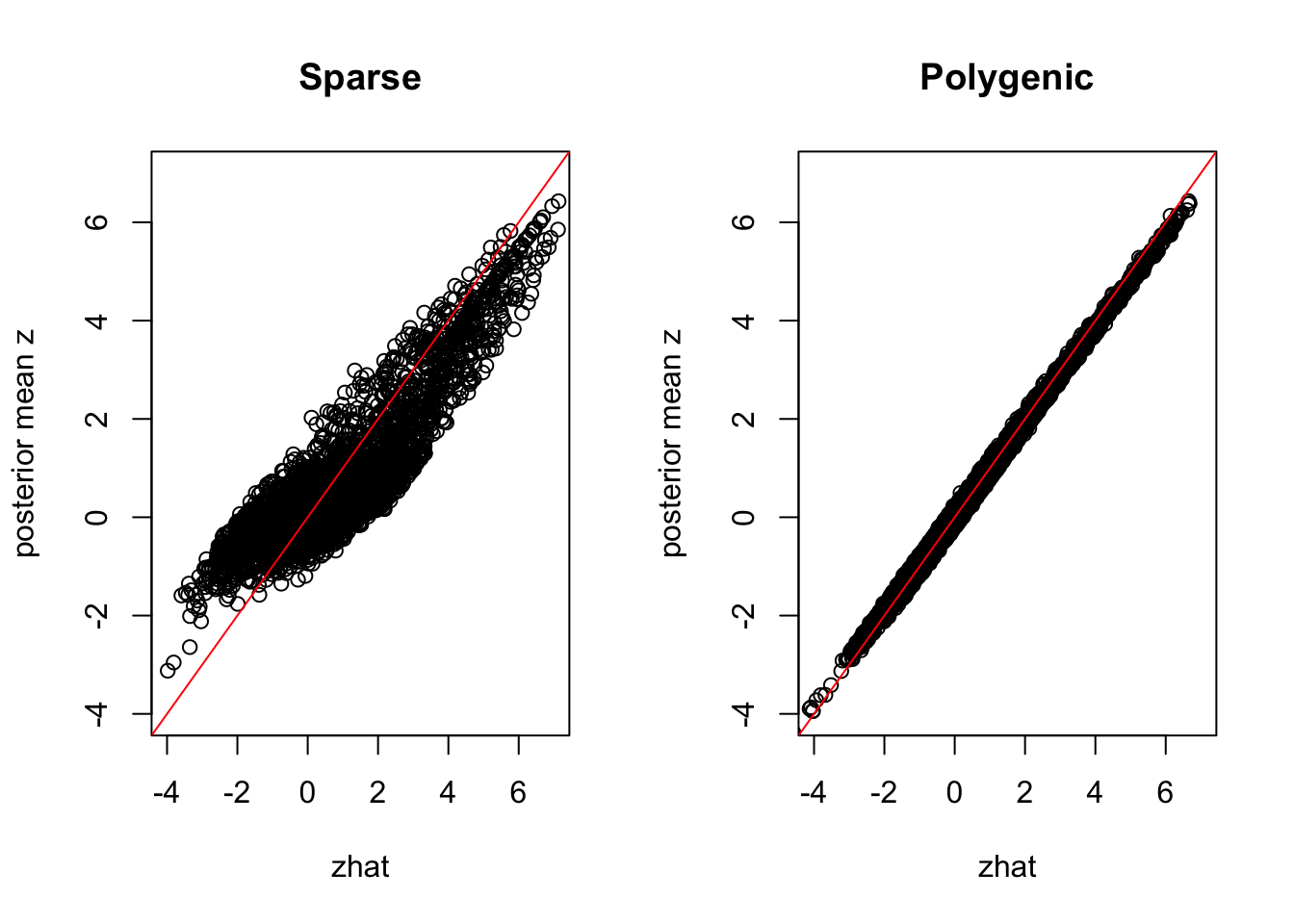
The interpretation of \(\sigma_0^2\) depends a lot on how polygenic the trait is. Even though we only simulate one non-zero effect, if we use a prior \(\pi_1 >> 0\) the model approaches a mean field approximation of ridge regression. Since ridge can estimate many small effects we get less shrinkage than if we enforce sparse architecture with \(\pi_1 \approx 0\).