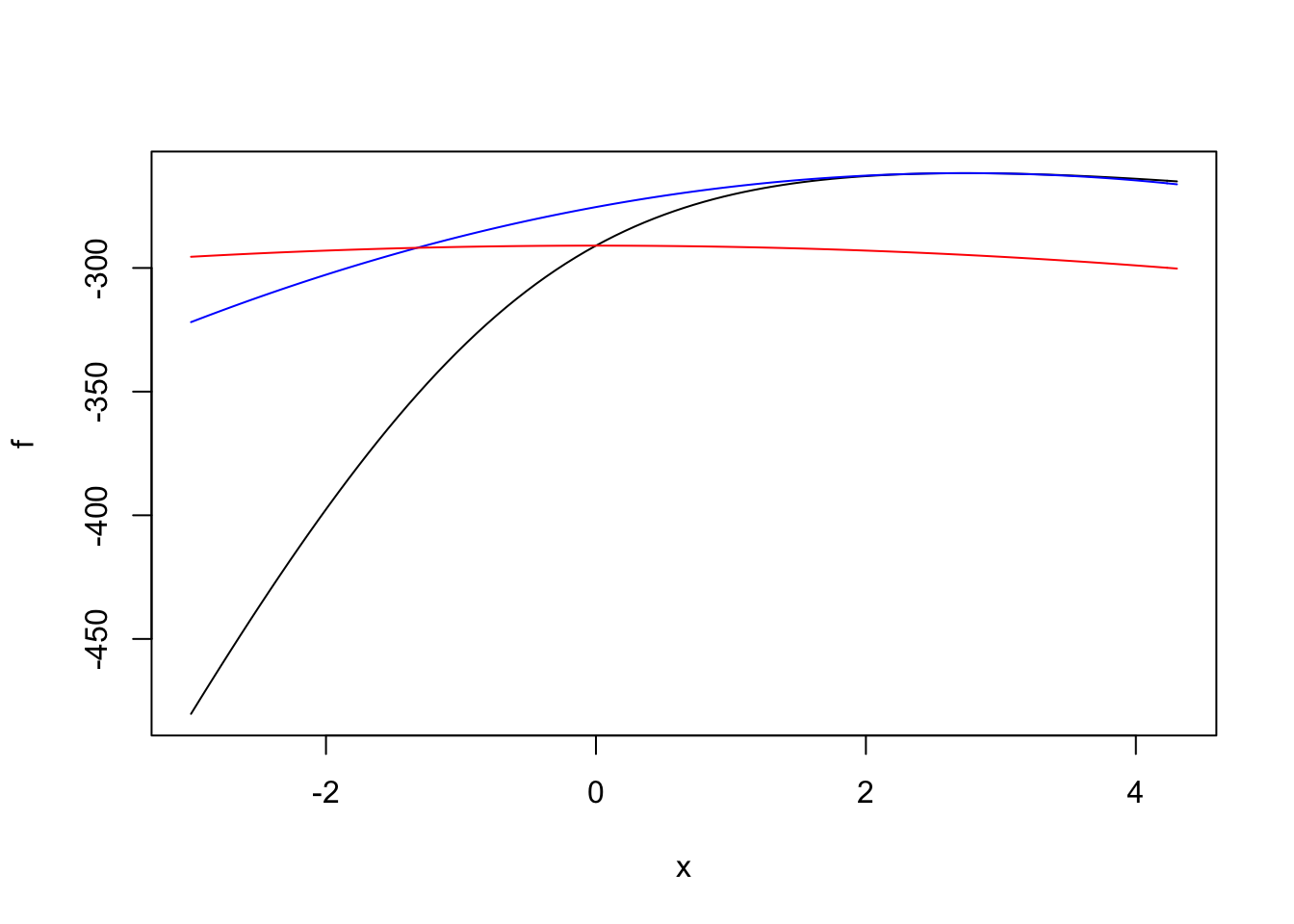
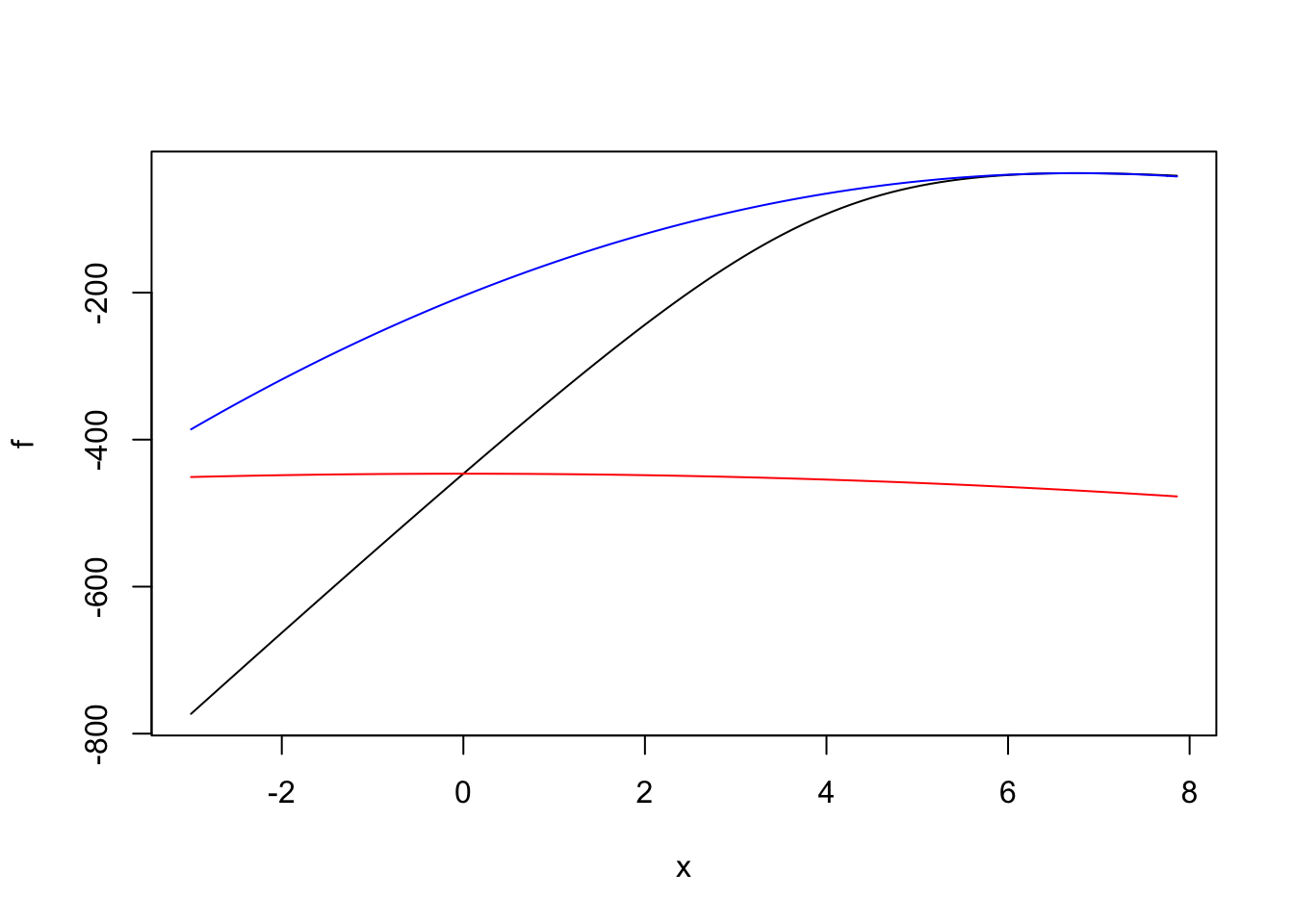
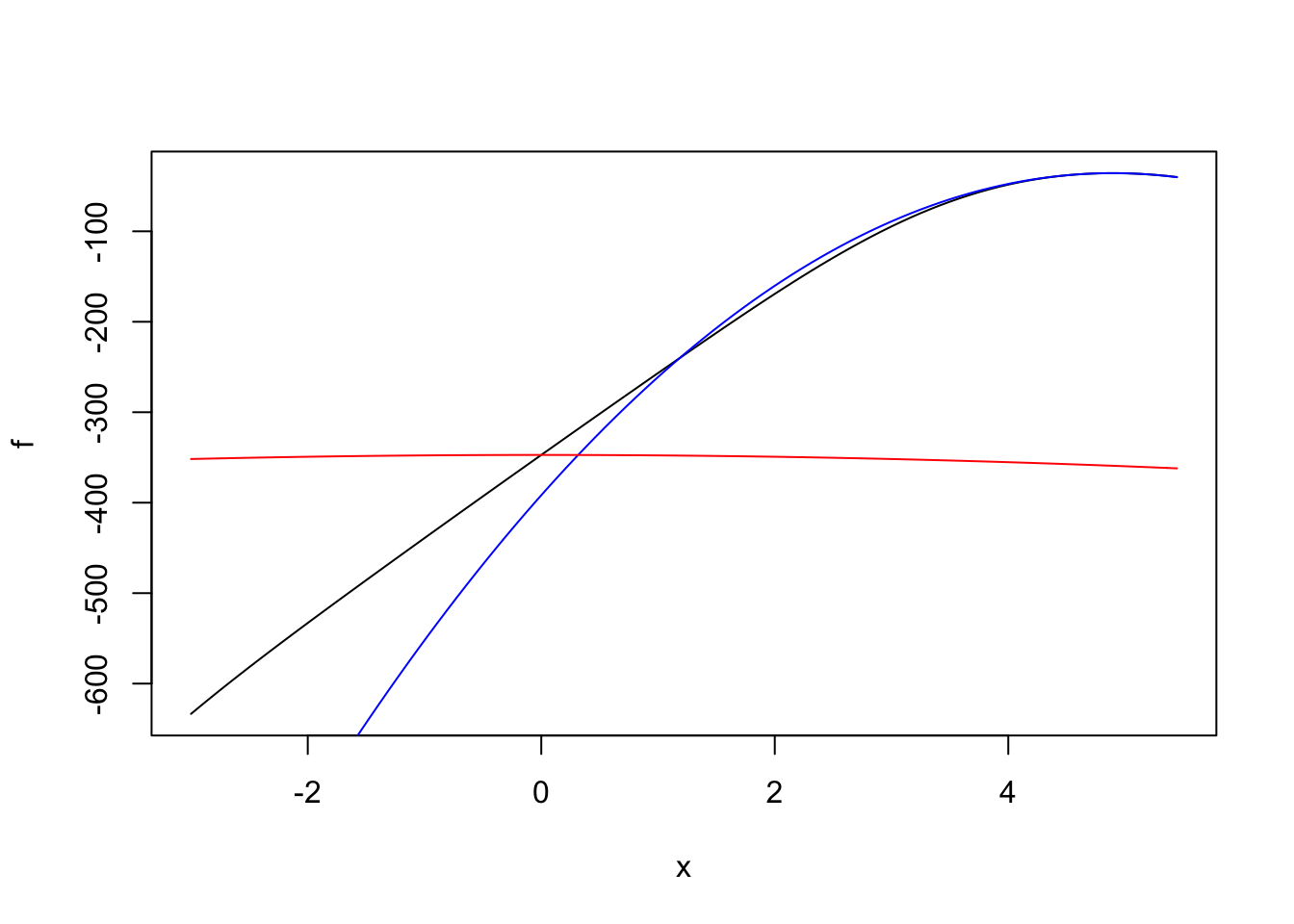
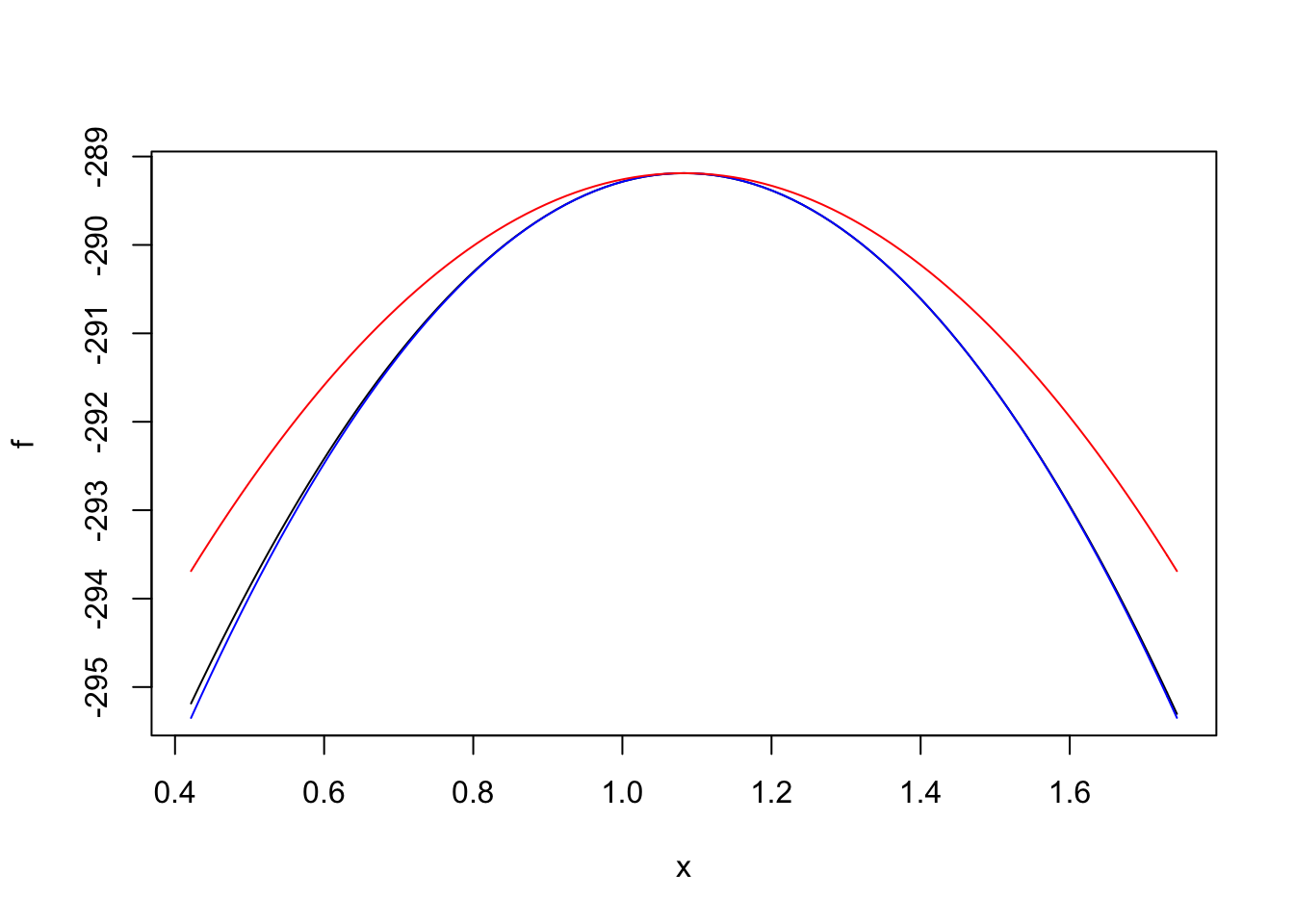
We take a look at Bayesian logistic regression with a fixex prior variance. We compare the performance of adaptive quadrature, Laplace approximation (with expansions around the MLE and MAP), and then Gauss-Hermite quadrature, which ought to refine the Laplace approximation.
Author
Karl Tayeb
Published
January 21, 2025
A few examples
Code
library(tictoc)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
Code
library(kableExtra)
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
Scenarios: - completely enriched (MLE does not exist, but the LR) - completely separated (\(x=y\), or \(y = 1(x \leq c)\)) - well behaved - c1-66
Code
##### Minimal working examplef <-paste0('', Sys.glob('cache/resources/C1*')) # clear cash so it can knitif(file.exists(f)){file.remove(f)}
[1] TRUE
Code
make_c1_sim <-function(){##### Minimal working example c1 <- gseasusie::load_msigdb_geneset_x('C1')# sample random 5k background genesset.seed(0) background <-sample(rownames(c1$X), 5000)# sample GSs to enrich, picked b0 so list is ~ 500 genes enriched_gs <-sample(colnames(c1$X), 3) b0 <--2.2 b <-3*abs(rnorm(length(enriched_gs))) logit <- b0 + (c1$X[background, enriched_gs] %*% b)[,1] y1 <-rbinom(length(logit), 1, 1/(1+exp(-logit))) list1 <- background[y1==1] X <- c1$X[background,] X <- X[, Matrix::colSums(X) >1] idx <-which(colnames(X) %in% enriched_gs)list(X = X, y = y1, idx = idx, b = b, b0 = b0, logits=logit)}
Code
# "completely enriched"sim1 <-function(n=500){set.seed(1) x <-rbinom(n, 1, 0.2) y <-rbinom(n, 1, 0.7) y[x ==1] =1return(list(x=x, y=y))}# "completely separated, binary x"sim2 <-function(n=500){set.seed(2) x <-rbinom(n, 1, 0.2) y <- xreturn(list(x=x, y=y))}# "completely separated, continuous x"sim3 <-function(n=500){set.seed(3) x <-rnorm(n) y <-as.integer(x >1.5)return(list(x=x, y=y))}# "regular simulation, binary x"sim4 <-function(n=500){set.seed(4) x <-rbinom(n, 1, 0.2) logit <--1+ x prob <-1/(1+exp(-logit)) y <-rbinom(n, 1, prob)return(list(x=x, y=y, logit=logit))}# "regular simulation, continuous x"sim5 <-function(n=500){set.seed(4) x <-rnorm(n) logit <--1+ x prob <-1/(1+exp(-logit)) y <-rbinom(n, 1, prob)return(list(x=x, y=y, logit=logit))}# "c1-GS66 examplesim6 <-function(n=500){ sim <-make_c1_sim() x <- sim$X[,66] y <- sim$yreturn(list(x=x, y=y, logit=sim$logits))}