Committee Meeting
6/5/23
Jaakkola-Jordan bound
Idea: construct local approximation to the log-likelihood. Tune the approximation to be tight near the posterior mode.
For all \(\xi \in \mathbb R\), \(\psi = {\bf x}^T \beta\)
\[ \log p(y | \psi) \geq \frac{1}{2} \log \sigma(\xi) + \frac{1}{2} \left((2y -1) \psi - \xi\right) - \frac{1}{4\xi}\tanh(\frac{\xi}{2}) (\psi^2 - \xi^2) \]
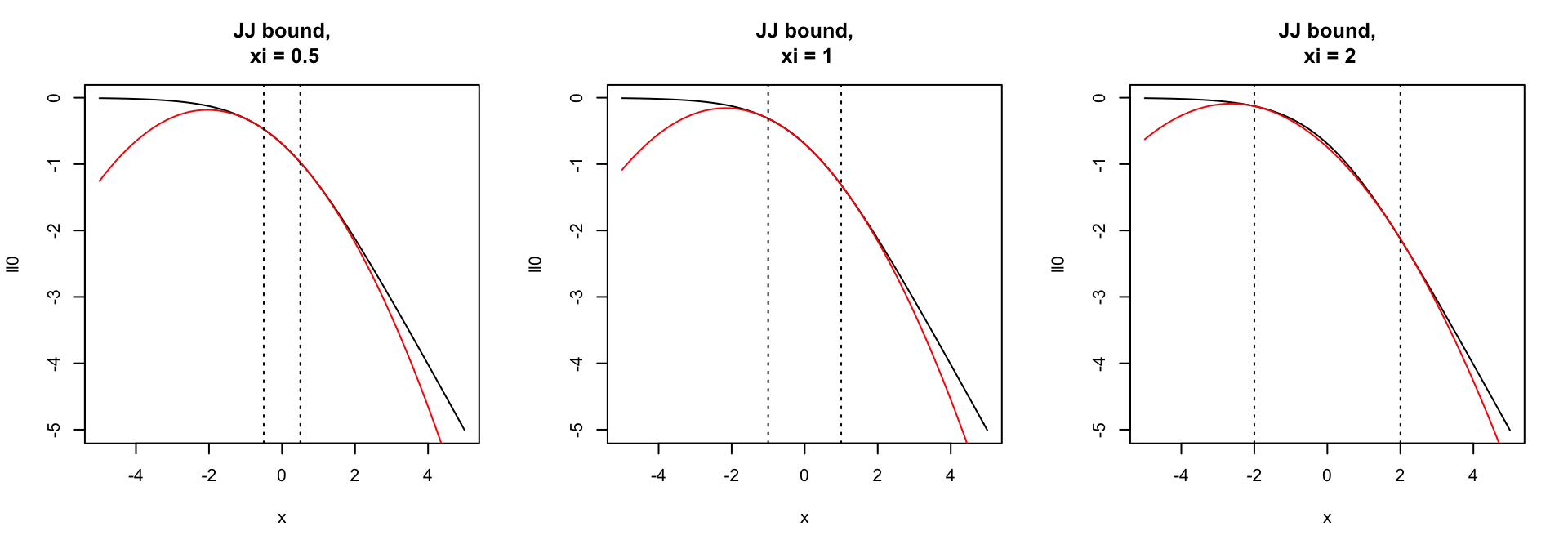
JJ Bound is bad for variable selection
Naive application of JJ bound to SER uses very loose ELBO for most variables
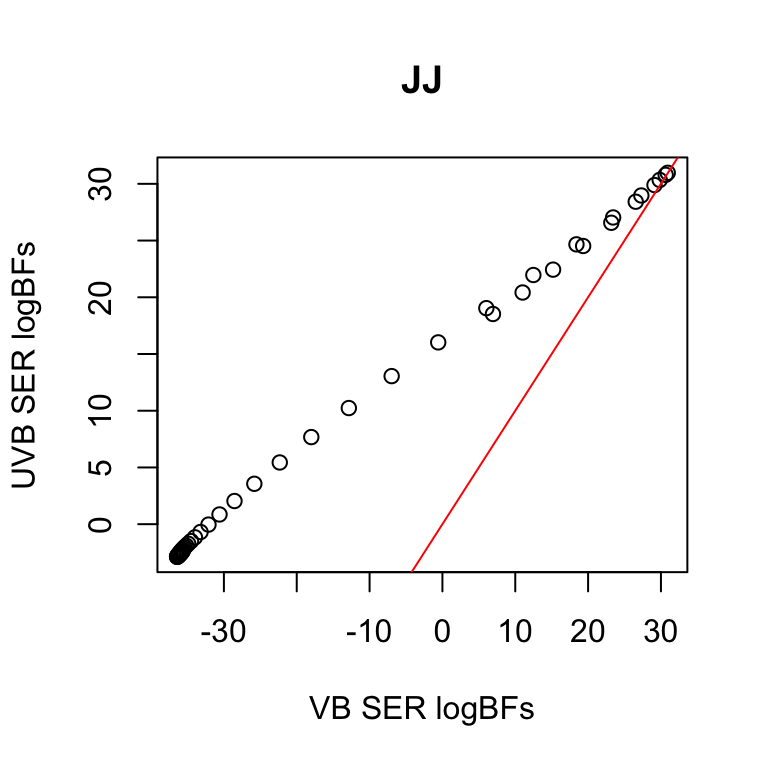
| method | coverage |
|---|---|
| uvb_ser | 0.945 |
| vb_ser | 0.845 |
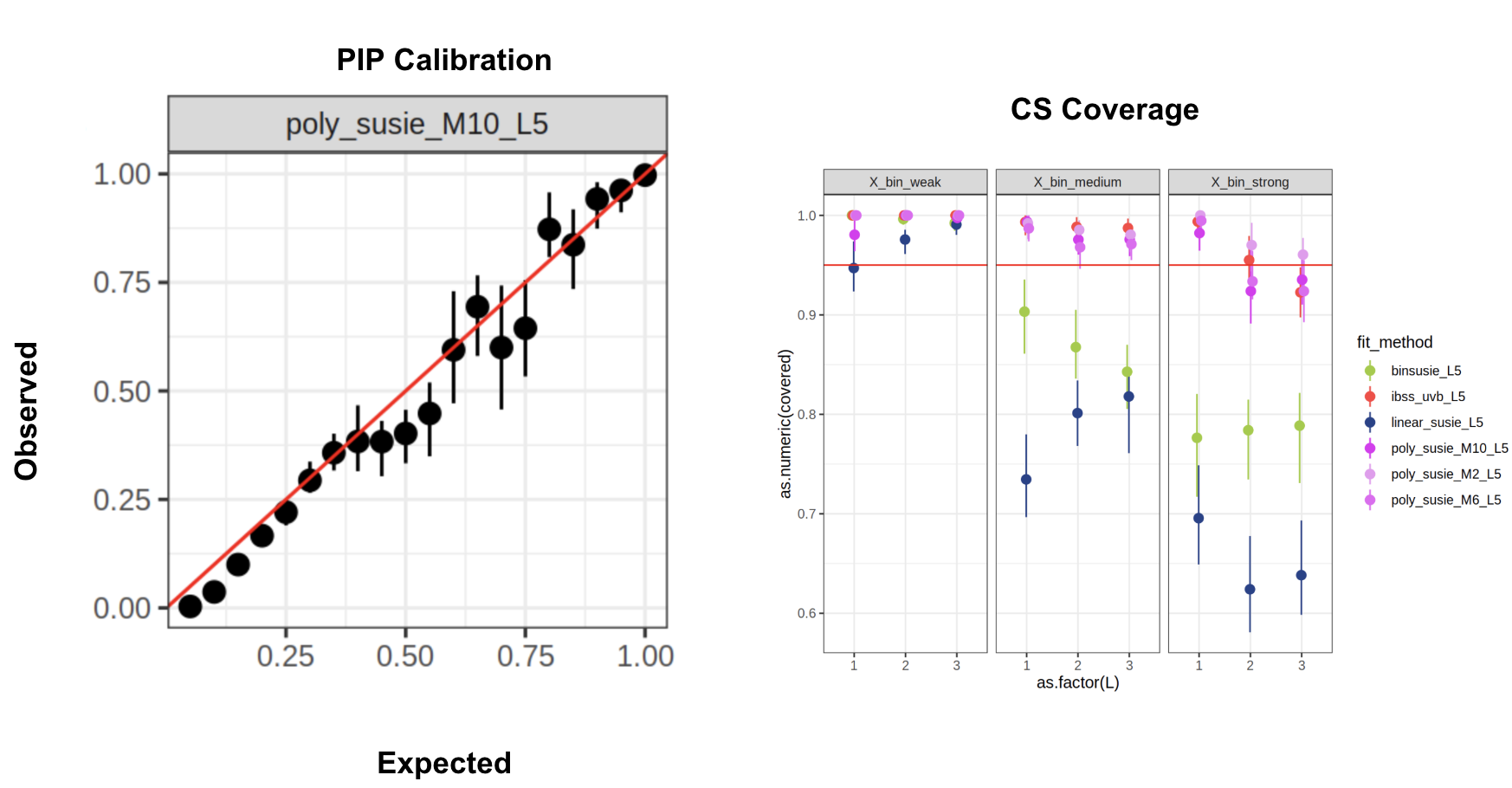
Simulations: VB logistic SuSiE \(L=5\)
Varying effect sizes, correlation structure, and num. of non-zero effects
Algorithm: Single effect regression
Require a function \(G\) which computes the BF and posterior mean of a Bayesian univariate regression
\[\begin{align} {\bf y} \sim 1 + {\bf x} + {\bf o} \\ b \sim N(0, \sigma^2) \end{align}\]

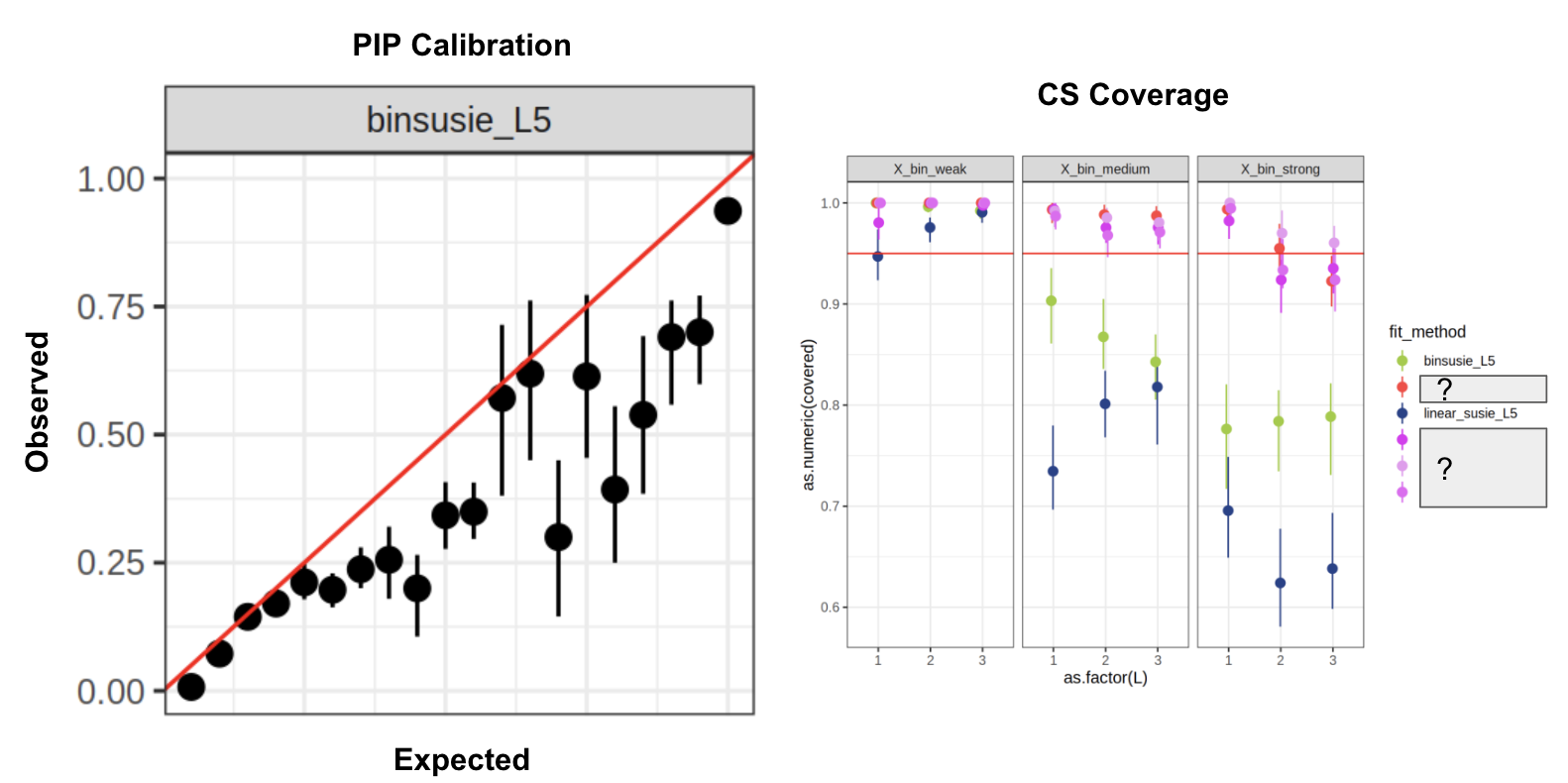
Algorithm: GIBSS

Simulations: logistic-GIBSS \(L=5\)
Much better performance compared to direct VB approach
A problem with ABF
- The asymptotic approximation may not be a good in the tails
- An issue for \(\hat\beta/s >> 0\)
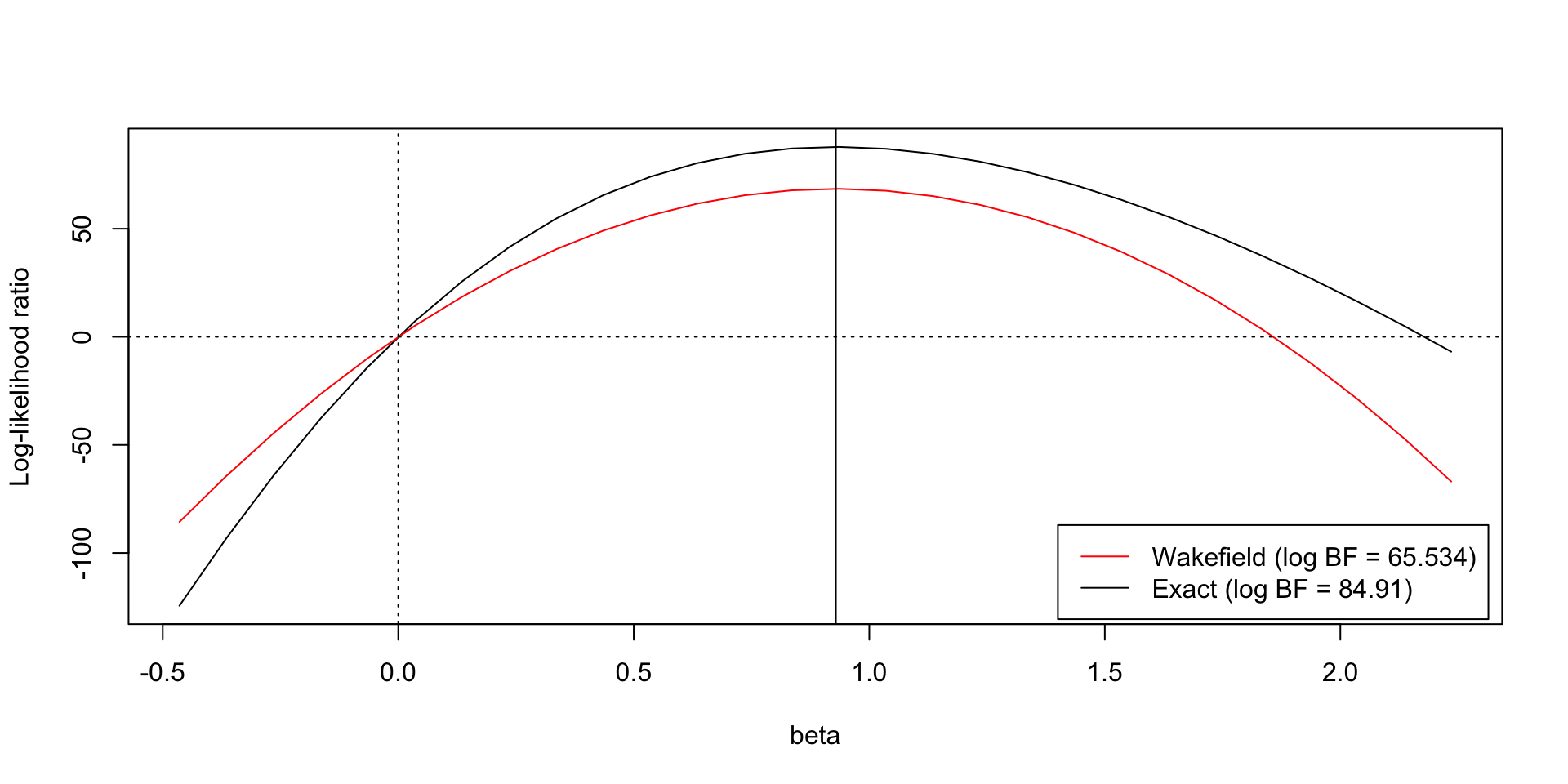
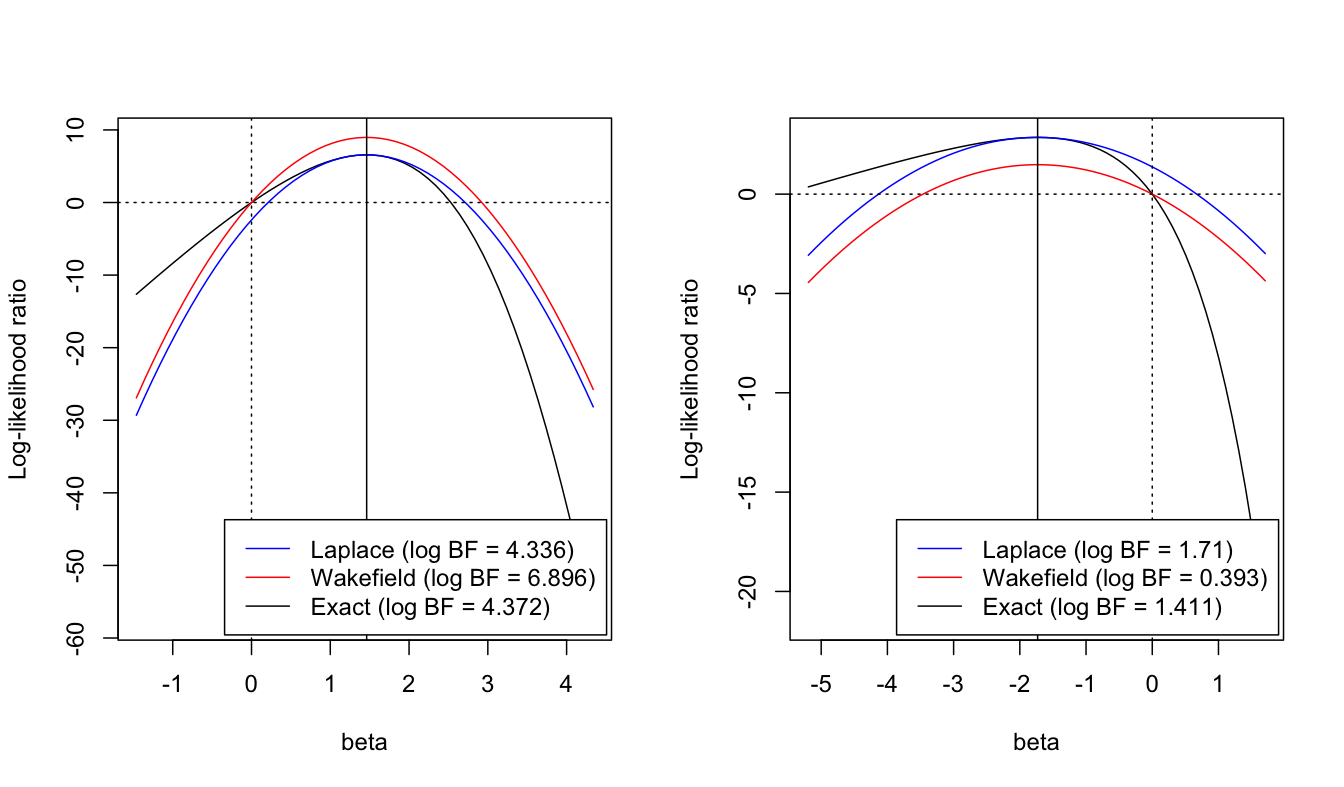
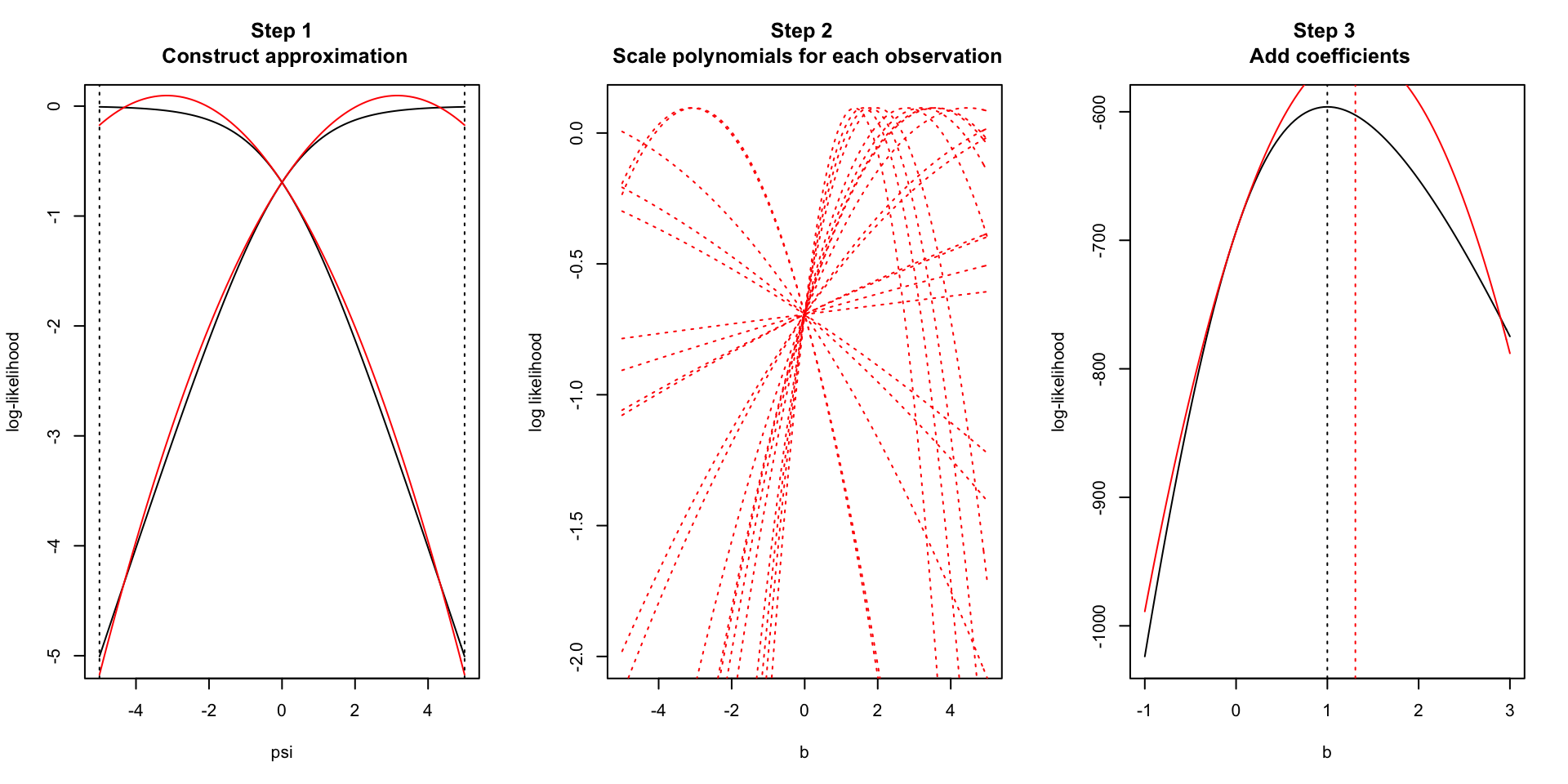
Corrected ABF/Laplace approximation
- Requires knowledge of the LR of the MLE against the null.
- Can dramatically improve approximation of the BF
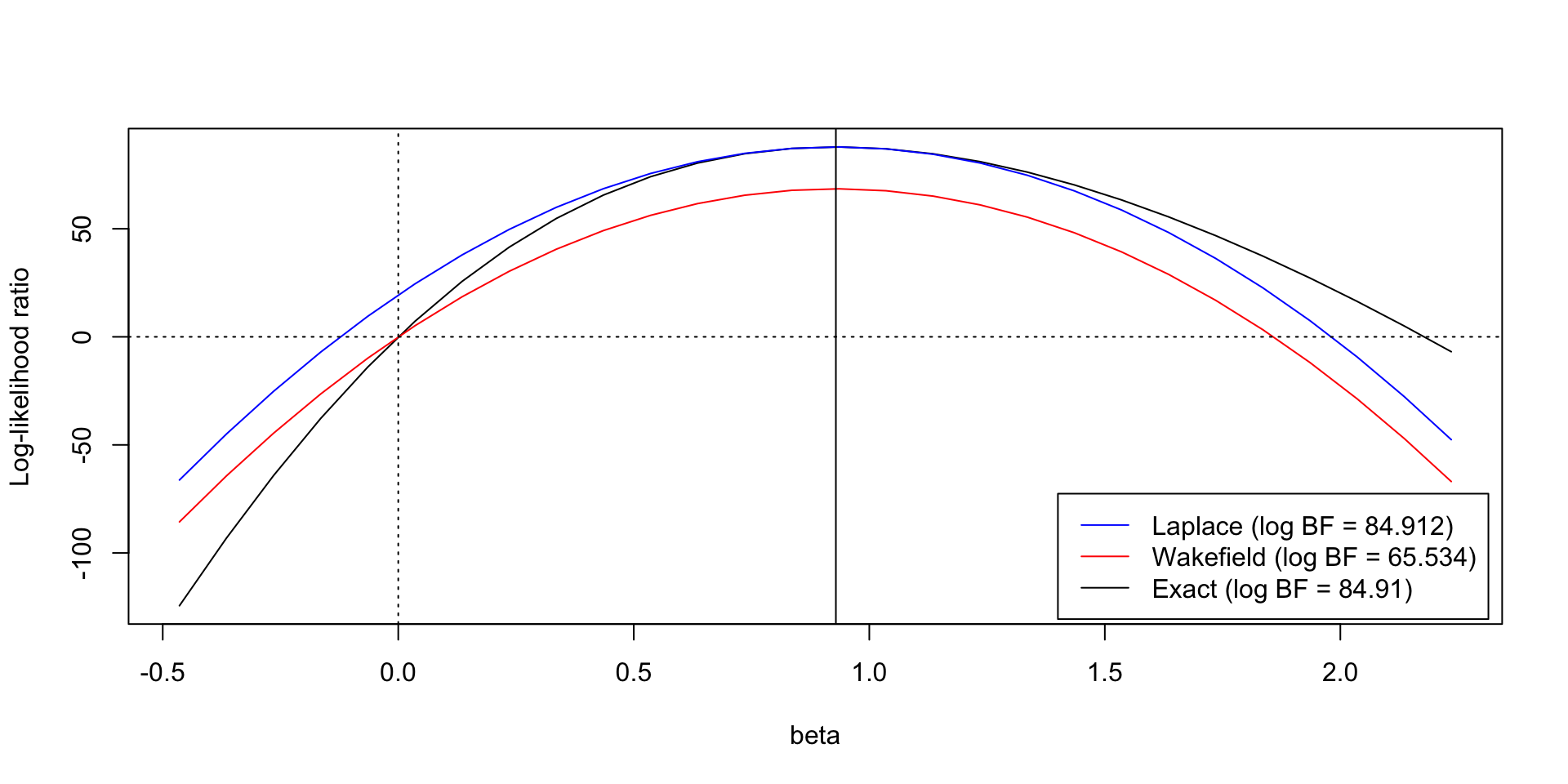
Comparison of logBF
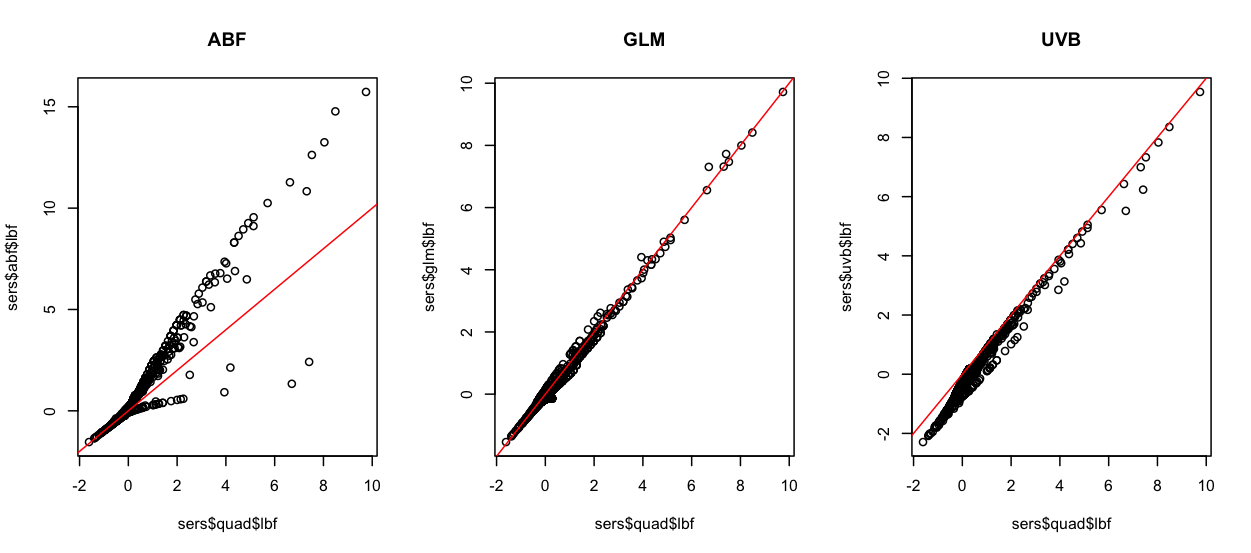
Comparison of logBF
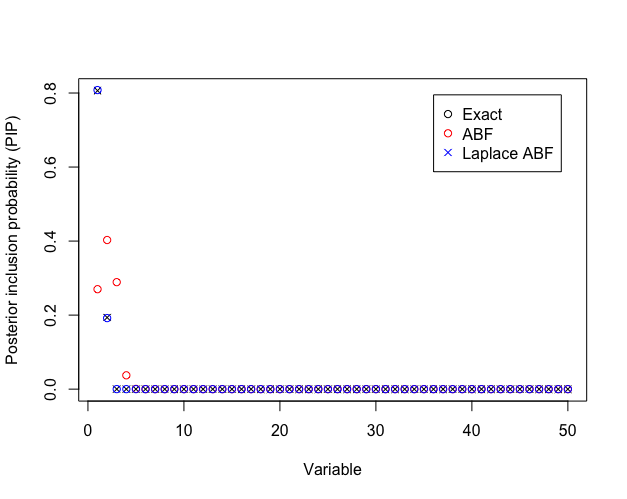
ABF Correction reorders PIPs
Example: univariate regression
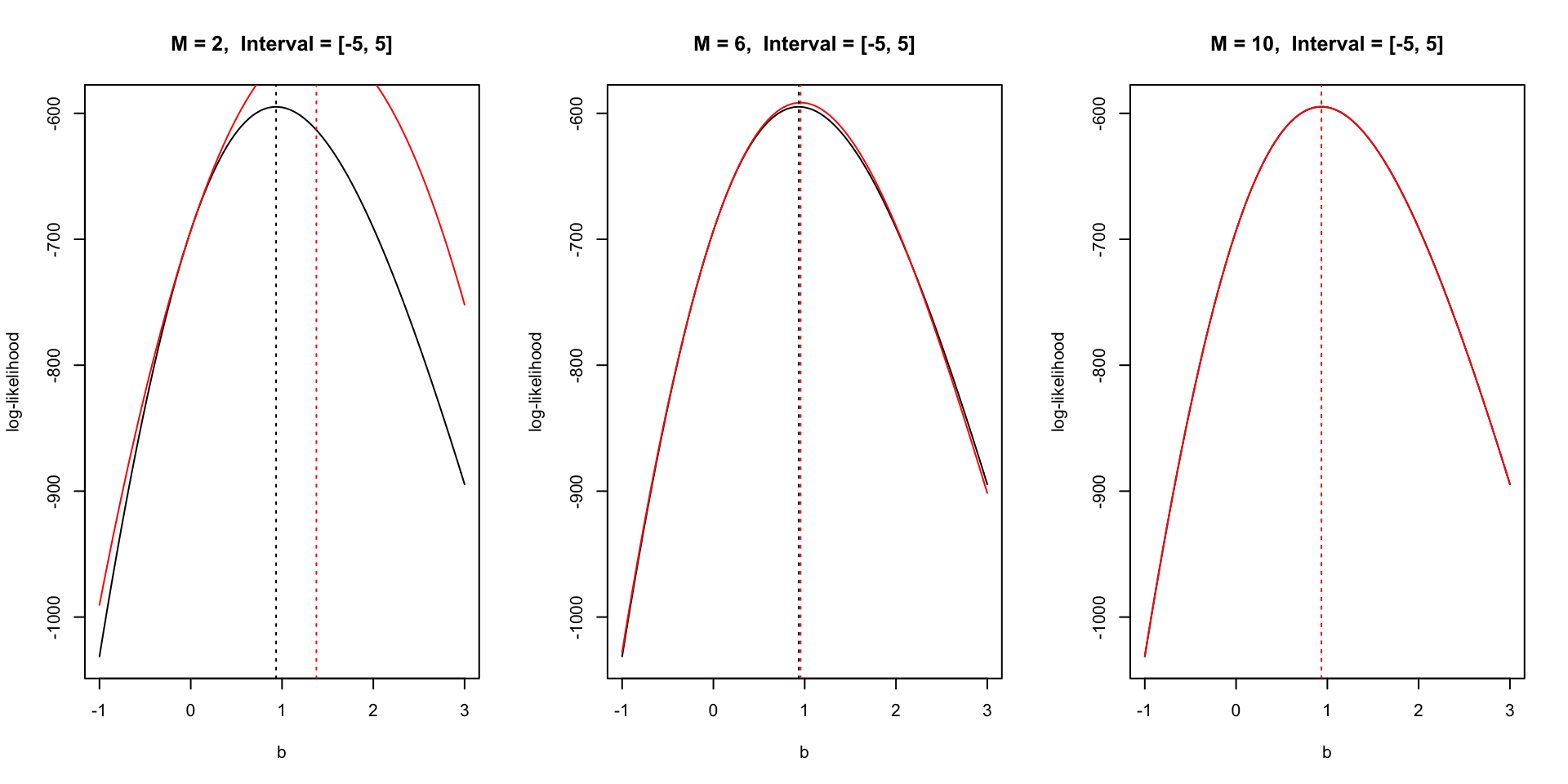
Increasing degree increases accuracy
Polynomial interpolation
\(f : \mathbb R \rightarrow \mathbb R\)
\(n+1\) distinct points \(x_0 < \dots < x_{n}\)
There exists a unique \(p \in P_n\) such that \(p\) interpolates \(f\) at \(x_0, \dots, x_n\).
\[\begin{align} p(x) = \sum_{i=0}^n f(x_i) L_{n, i}(x), \quad L_{n, i}(x) = \prod_{k \neq i} \frac{x - x_k}{x_i - x_k} \end{align}\]
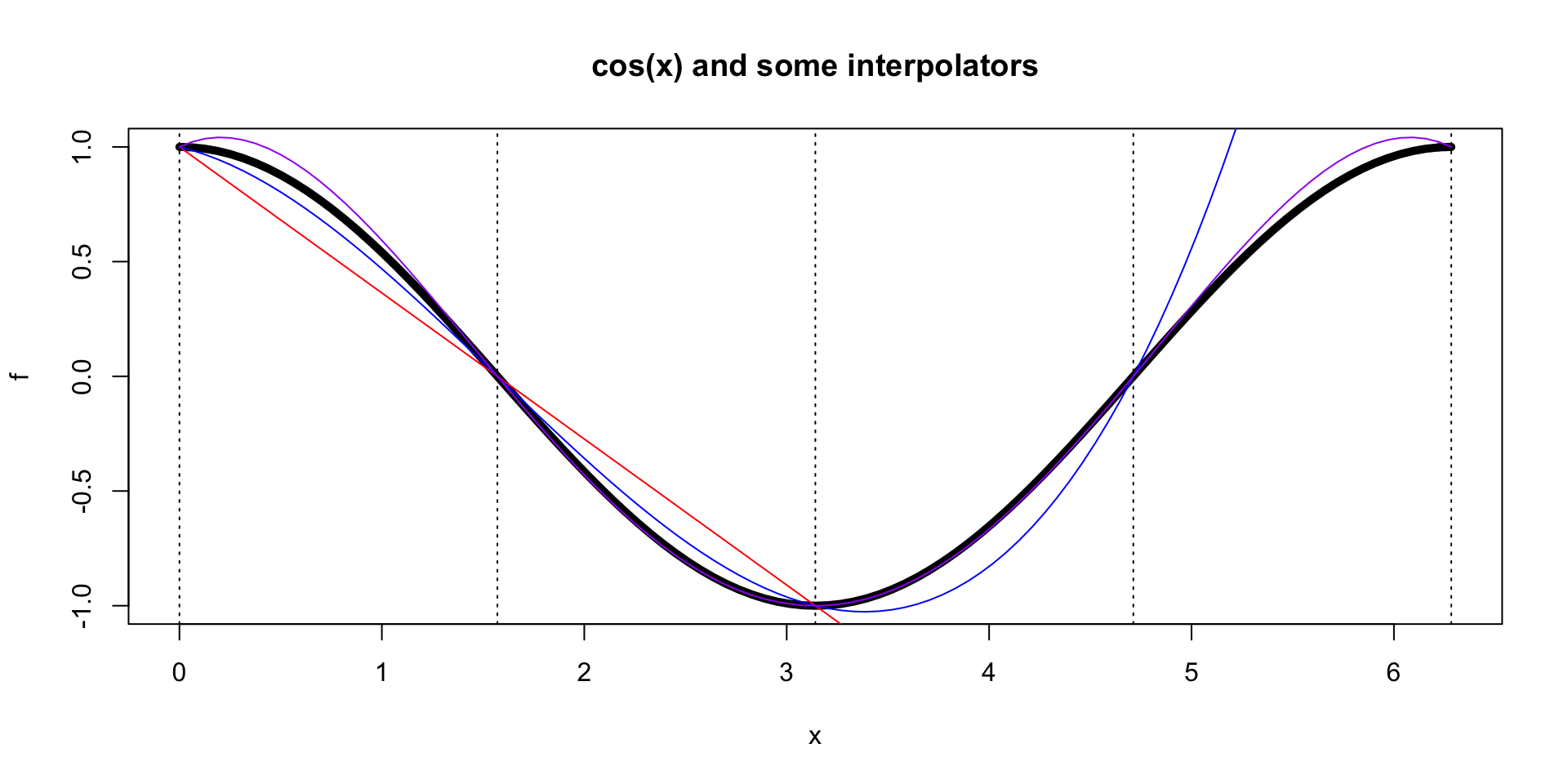
Chebyshev interpolation
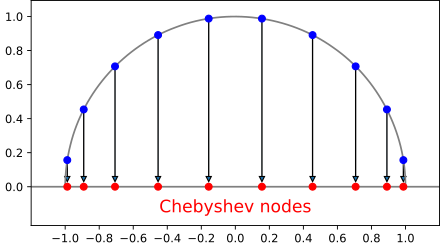
Interpolation at the zeros of Chebyshev polynomials \(x_k = \cos \left(\frac{2k-1}{2M}\pi \right), k = 1, \dots, M\)
Fast interpolation via re-scaled DFT of \(f(x_1), \dots, f(x_M)\)
Approximately minimizes \(||f - \hat f||_{\infty}\)
Chebyshev interpolation: GLM likelihoods
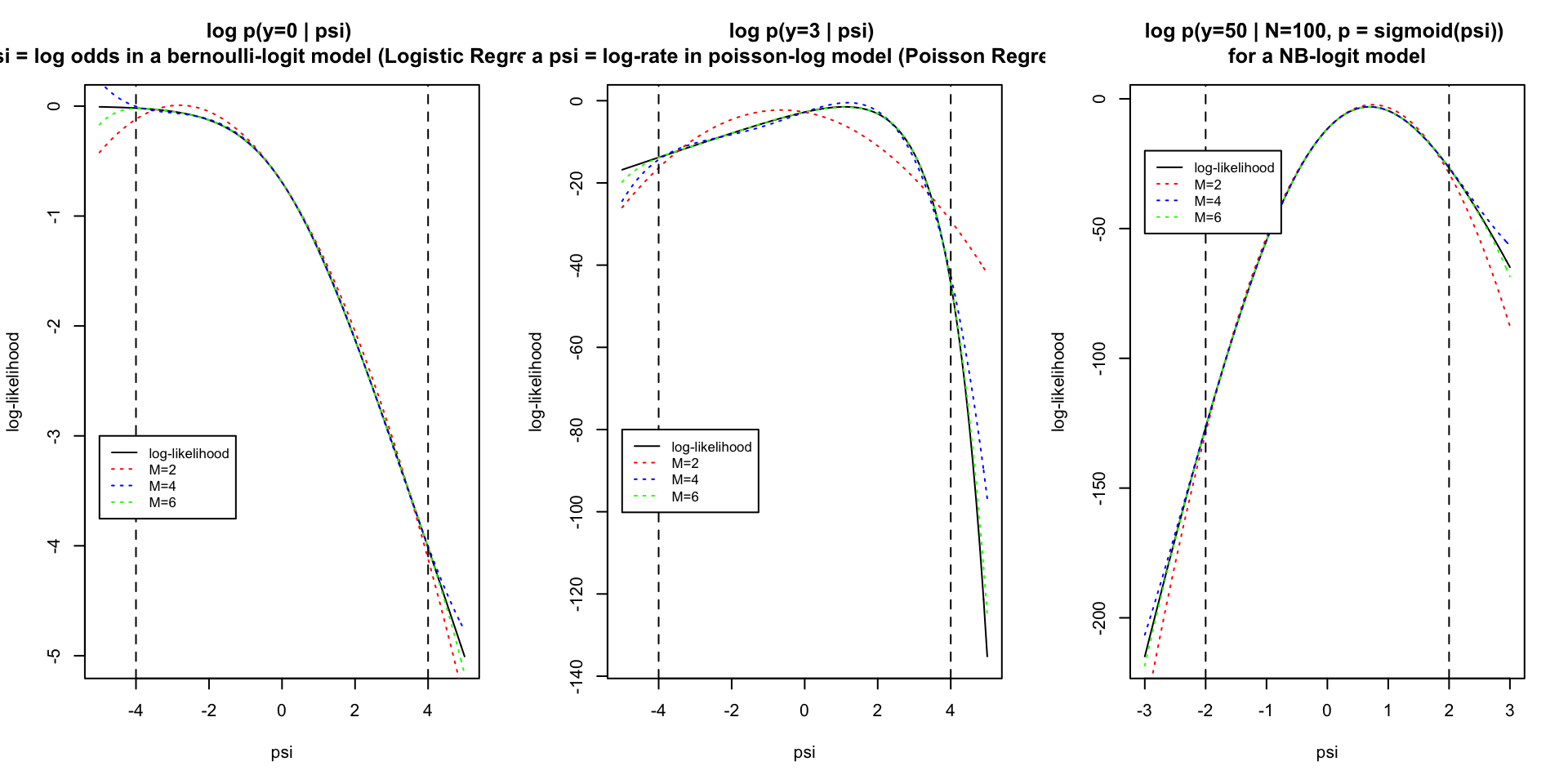
Simulations